![#통계학개론 12-1 #상관계수(1) #상관계수의개요 [자막]](https://i.ytimg.com/vi/RymrCV3K5J8/hqdefault.jpg)
자기 상관은 시계열 분석에 사용되는 통계적 방법입니다. 목적은 다른 시간 단계에서 동일한 데이터 세트에서 두 값의 상관 관계를 측정하는 것입니다. 시간 데이터가 자기 상관을 계산하는 데 사용되지는 않지만 의미있는 결과를 얻으려면 시간 증분이 같아야합니다. 자기 상관 계수는 두 가지 목적을 제공합니다. 데이터 세트에서 비 랜덤 성을 감지 할 수 있습니다. 데이터 세트의 값이 무작위가 아닌 경우 자기 상관을 통해 분석가가 적절한 시계열 모델을 선택할 수 있습니다.
분석중인 데이터의 평균 또는 평균을 계산하십시오. 평균은 모든 데이터 값의 합계를 데이터 값 수 (n)로 나눈 값입니다.
계산을위한 시간 지연 (k)을 결정하십시오. 지연 값은 하나의 값을 다른 값과 구분하는 시간 단계를 나타내는 정수입니다. 예를 들어, (y1, t1)과 (y6, t6) 사이의 지연은 5입니다. 두 값 사이에 6-1 = 5 개의 시간 간격이 있기 때문입니다. 임의성을 테스트 할 때 일반적으로 지연 k = 1을 사용하여 하나의 자기 상관 계수 만 계산하지만 다른 지연 값도 작동합니다. 적절한 시계열 모델을 결정할 때는 각기 다른 지연 값을 사용하여 일련의 자기 상관 값을 계산해야합니다.
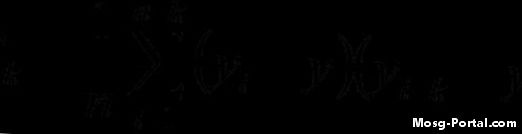
주어진 공식을 사용하여 자기 공분산 함수를 계산합니다. 예를 들어, 지연 k = 7을 사용하여 세 번째 반복 (i = 3)을 계산 한 경우 해당 반복에 대한 계산은 다음과 같습니다. (y3-y-bar) (y10-y-bar) 모두 반복 "i"값을 구한 다음 합계를 가져 와서 데이터 세트의 값 수로 나눕니다.
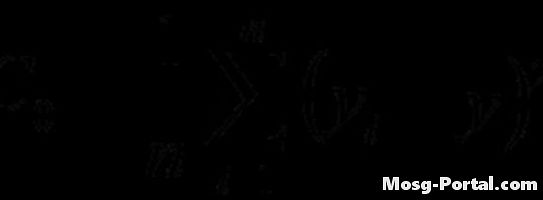
주어진 공식을 사용하여 분산 함수를 계산하십시오. 계산은 자기 공분산 함수의 계산과 유사하지만 지연은 사용되지 않습니다.

자기 공분산 함수를 분산 함수로 나누면 자기 상관 계수를 얻을 수 있습니다. 표시된대로 두 함수에 대한 공식을 나누어이 단계를 건너 뛸 수 있지만, 다른 목적으로 자기 공분산과 분산이 필요한 경우가 많으므로 개별적으로 계산하는 것이 실용적입니다.